














Webサイトの動的スクレイピングを行うため、Seleniumを使用できる環境を構築しました。
PythonからSeleniumを使用する
Seleniumとは
SeleniumとはWebサイトの動的スクレイピングを行う事ができるパッケージです。サイトが静的である場合、すなわち表示された状態から変化がない場合にはBeautiful SoupやPandasでもスクレイピングが可能ですが、javascript等を使用していて、ユーザ操作によってサイトの表示が変わったり、ログイン画面での認証が必要といった場合には扱いが困難となります。
一方、Seleniumはブラウザを操作するようにWebサイトを扱えますので、動的なサイトの取り扱いも可能となります。実際には、Seleniumはブラウザごとに用意されたWebDriverを通じてブラウザ操作を行っています。
Seleniumは多くのプログラミング言語で使用可能ですが、ここではChromebook上のLinux環境でPythonからSeleniumを利用してスクレイピングを行える環境を整えていきます。
Seleniumのインストール
Seleniumのインストールはpipを使用できますので簡単です。以下の通り、pip installを実行するだけです。
$ pip install seleniumWebDriverのインストール
Seleniumをインストールしただけではスクレイピングを実現する事はできません。
上述の通り、SeleniumはWebDriverを通じてブラウザ操作を行いますので、使用するブラウザに合わせたWebDriverをインストールする必要があります。
Webで検索を行うと、Linux環境ではChromeDriverを使用するという記事が多く出てきます。以下のサイトからZIPファイルをダウンロードし、展開してバイナリファイルをパスの通ったディレクトリに置く、というのが基本的なやり方です。

ですが、私の使用するChromebookではこの方法は使えませんでした。私の使用するChromebookはacer製のARM64アーキテクチャのものですが、上記のダウンロードサイトではARM64アーキテクチャのLinux向けファイルは用意がありませんでした。
そこで、代替方法としてChromiumを使用します。aptを使用してChromiumDriverのインストールを行います。
$ sudo apt update && sudo apt install chromium-driver
$ which chromedriver
/usr/bin/chromedriver上記の通り、パスが通っている事が確認出来たら完了です。
実行テスト
さて、それでは早速テストを行ってみます。
Pythonで以下のコードを書いてみます。実行してみて、ブラウザが立ち上がり、【Yahoo! JAPANトップページ】→【検索結果ページ】と画面遷移できたら成功です。
from selenium import webdriver
from selenium.webdriver.common.by import By
# WebDriverの起動
driver = webdriver.Chrome()
driver.get("https://www.yahoo.co.jp")
# 検索キーワードを入力
element = driver.find_element(By.NAME, "p")
element.send_keys("Selenium")
# 検索ボタンをクリック
element =driver.find_element(By.TAG_NAME, "button")
element.click()1-2行目:パッケージのインポート
パッケージをインポートします。2行目でByをインポートしています。
WebでSelenium関連で要素を取得する方法を調べると、find_element_by_nameとかfind_element_by_idという関数を使う方法が紹介されていたりしますが、現在は非推奨となっていますので、Byをインポートしてfind_element関数でByが使えるようにしておきます。
9行目、13行目:Webサイト要素の取得
Webサイトの要素を取得します。
今回はBy.NAMEとBy.TAG_NAMEを使用していますが、詳しい使い方は以下のサイトを参照してみてください。

By.XPATHがおススメ
個人的にはBy.XPATHがおススメです。最初はとっつきにくいですが、これを使えば他は必要ないのではないかと思えるほどです。HTML構造を調べてビシッと目的の要素を取得するにはとても便利です。これを使うと以下のようなことが実現できます。
- 任意の属性を使っての検索
Byクラスで用意されているものでは、id、class、nameといった用意されている属性だけでしか検索ができませんが、By.XPATHを使うと[](スクエアブラケット)と@(アットマーク)を使って任意の属性で検索ができます。 - 複数条件での検索
要素を探すときに、一つの属性だけですと同じものが複数見つかってしまうといったことがあります。そんな時に、and / or / notを使って絞り込んでいく事ができます。 - HTML構造を利用した検索
仮に以下のような構造のHTMLツリーがあったとします。この場合に緑色の要素を取得する事を考えます。By.CLASS_NAMEで取得しようとすると、同じclass属性を持つ水色の要素も対象としてしまい、狙い通りの要素取得が行えません。
このような時、By.XPATHを使うと、その親要素である<div>のidが異なることを利用して狙い通りに緑色の要素を取得する事が出来ます。
具体的には以下のようなコードで取得する事が出来ます。
element = driver.find_element(By.XPATH, "//div[@id='B']/a[@class='C']")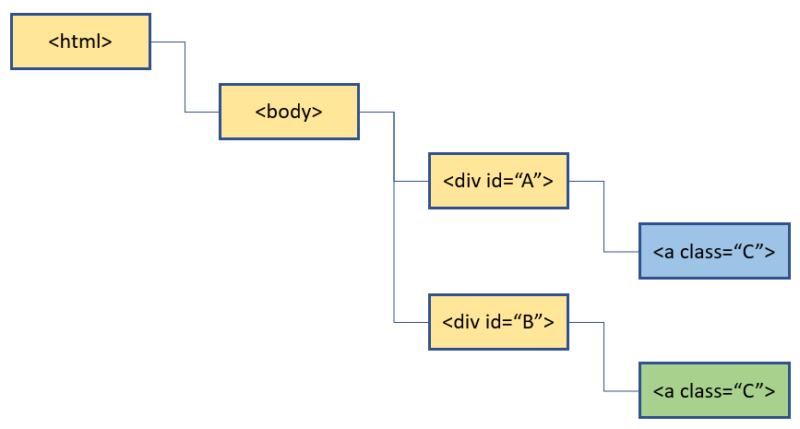
- 前方一致、後方一致、キーワード検索
starts-with、ends-with、containsを使用して、前方一致、後方一致、キーワード検索が使用できます。 - ノードを使った検索
ある特定の要素を見つけて、そこからの相対位置として要素を検索する事ができます。特徴的な属性を持つ要素をまず見つけて、そこから近くの要素を探す場合に便利です。例えば、上記の緑のセルを<div id=”A”>から検索する場合には、以下のような記述が使えます。
element = driver.find_element(By.XPATH, "//div[@id='A']/preceding-sibling::div/a[@class='C']")他にも色々な使い方ができます。XPATHの詳しい解説は以下のサイトが参考になります。



コメント